来源
雪花算法(Snowflake)是一种生成分布式全局唯一ID的算法,生成的ID称为Snowflake IDs或snowflakes。这种算法由Twitter创建,并用于推文的ID。Discord和Instagram等其他公司采用了修改后的版本。
格式
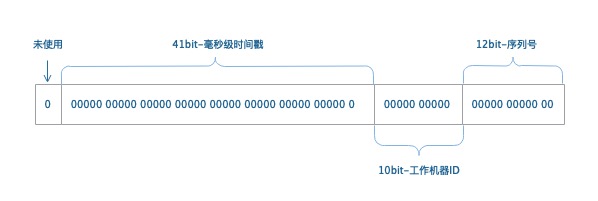
一个Snowflake ID有64位。前41位是时间戳,表示了自选定的时期以来的毫秒数。 接下来的10位代表计算机ID,防止冲突。 其余12位代表每台机器上生成ID的序列号,这允许在同一毫秒内创建多个Snowflake ID。最后以十进制将数字序列化。
SnowflakeID基于时间生成,故可以按时间排序。 此外,一个ID的生成时间可以由其自身推断出来,反之亦然。该特性可以用于按时间筛选ID,以及与之联系的对象。
范例
2022年六月由@Wikipedia所发的一条推文的雪花ID是1541815603606036480。这个数字被转换成二进制就是0 0101 0101 1001 0110 1000 0100 0111 1101 1000 1000|01 0111 1010|0000 0000 0000,其中以竖线分隔成三个部分。
64位的二进制所示
- 最高位表示符号位
- 后面的41bit是产生该ID的unix毫秒时间戳
- 10bit是机器编号,最多可以部署在 2^8 = 1024 机器上
- 12bit 序列号,同一毫秒最多可以产生 2^12 = 4096 个序列号
算法实现思路
时间戳左移22位,机器编号左移12位,序列号不动,三者按位或运算,得到一个64位二进制,再转成10进制,就是雪花ID
反之,根据雪花ID可以反推导出机器ID,时间戳,序列号
41位时间戳2^41/(1000360024*365) ≈ 69.73057年,引入 epoch基准时间,是为了能是雪花ID能使用的时间更长一点,41位时间戳按照unix时间,最多只能到2039-09-07 23:47:35
省流不看系列
github jokechat/guid1
2docker run --rm -p 8080:80 jokechat/guid:v1.0.3
curl 127.0.0.1:8080
1 | { |
代码实现
type.go
1 | package snowflake |
snowflake.go
1 | package snowflake |
id.go
1 | package snowflake |
1 | func main() { |